
Sans être Hamlet, mais ayant pu intégrer le programme bêta de test de ChatGPT sur Bing, je dois dire que c’est assez impressionnant, surtout depuis la version 4.
Un Français irréprochable, chose dont on avait perdu l’habitude, et, surtout, l’impression par moment de clavarder avec une vraie personne.
Alors forcément, on se demande ce qu’est une IA dite générative et l’on se rend rapidement compte qu’il y a d’énormes similitudes avec ce que peut faire tout un chacun : établir des corrélations et préparer une réponse adaptée. Il n’en reste pas moins que cela risque d’aggraver plusieurs problèmes et d’en créer de nouveaux.
La faute à l’IA ? Sans doute pas.
Une fois n’est pas coutume, c’est d’abord sous l’angle philosophique que nous allons aborder la question et, comme vous n’êtes pas obligés de me croire sur parole, nous allons dérouler un peu le tapis pour faire un accueil éclairé à l’IA générative.
De l’intelligence, art y ficelle
Sans rentrer dans les différentes théories de l’intelligence (jusqu’à 8 selon Howard Gardner), il est certain que sur le plan des démarches inductives, les IA actuelles ont des performances bien supérieures au cerveau humain dans leur domaine de spécialité.
Pour faire simple, il s’agit de la capacité à établir une réponse (sortie) appropriée en fonction des flux d’entrée. ChatGPT, par exemple, sera capable de résumer un texte en quelques secondes.
De manière similaire aux robots qui ont remplacé l’homme sur les chaînes de production, une IA générative a un rendement inégalé dans l’analyse et la manipulation du langage naturel. Il n’en reste pas moins un outil hautement spécialisé. C’est un premier piège. On a tous tendance à penser, par une sorte d’ontologie inversée, que le langage est nécessairement la marque d’une certaine qualité intellectuelle.
Dominer le langage, c’est apprendre à penser, et de surcroît, c’est une manière de développer la sensibilité, l’imagination, l’esprit critique
Mario Vargas Llosa
Les IA, toutes, y compris celle que vous entraînez bénévolement à la reconnaissance d’image par les Google recaptcha, sont toutes sur un modèle inductif. Quoi de mieux pour comprendre que de regarder comment cela se passe sur un cas « simple » :
Pour ceux qui se demanderaient quelle est l’architecture de ChatGPT, voici un article en donnant les grandes lignes.
A ce stade, il y a au moins deux aspects inhérents à la construction des IA qui devrait vous interpeller.
Internal Affairs, tout un programme !
D’une part, une IA inductive sera forcément limitée par un répertoire connu. De plus, par sa nature heuristique, elle aura nécessairement tendance à se tenir à la tendance majoritaire (voire artificiellement majoritaire si son éducateur a sciemment tronqué sa base d’apprentissage).
Pour mieux comprendre, on peut parcourir les échanges entre Jean-Pierre Petit et ChatGPT à propos de la théorie du modèle cosmologique Janus défendu par le premier :
On peut notre plusieurs choses intéressantes. D’une part, les données de l’échange sont stockées pour permettre de poursuivre l’apprentissage de l’IA. D’autre part, ChatGPT utilise une vieille astuce du dialogue interpersonnel consistant à reprendre les propos de son interlocuteur : affirmer que l’on comprend, tout en restant sur son propos initial.
La réaction du chercheur est intéressante car il tombe dans « le piège » et choisit de retenir dans la reformulation de ChatGPT ce qui le conforte dans ses idées alors que, sur le fond, celle-ci rabâche toujours la même chose. Nul doute que l’IA a été entraînée pour satisfaire au principe de l’écoute active.
D’autre part, en dehors de son domaine d’apprentissage (comprendre et écrire le langage naturel), une IA générative sera totalement inutile. Exemple en image :
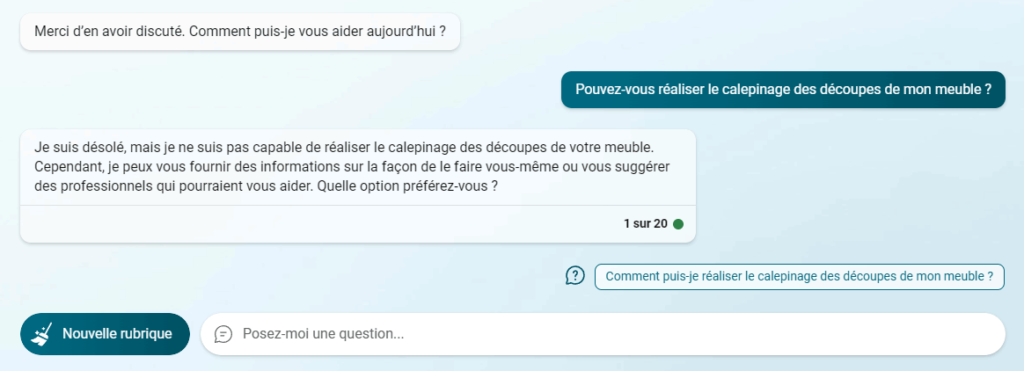
Évidemment, d’autres IA spécialisées sont, elles, tout à fait capables d’optimiser les découpes pour limiter les pertes. Dans le cas des IA génératives, c’est le fait de pouvoir traiter le langage naturel qui est leur spécialité, ce qui induit un biais de perception sur l’intelligence réelle de l’interlocuteur.
Moteur de recherche vs moteur de réponse
Après les écueils endogènes à toute IA liés à sa programmation et son éducation, il reste sans doute le plus gros morceau, à savoir son utilisation par l’Homme.
Né en 1975, internet est arrivé dans ma vie en même temps que l’ENITA de Bordeaux. On n’y trouvait pas grand chose à l’époque sinon un débit abominable. Cela ressemblait à cela : https://dejavu.org/1995win.htm. La recherche se faisait surtout sur Yahoo dont le contenu, catégoriel, était alimenté sur proposition des uns et des autres. C’était artisanal en somme. Les résultats de recherche aussi d’ailleurs.
Quand on voulait des statistiques agricoles par exemple, on s’adressait, par courrier ou téléphone, à la DDA (DDT maintenant) du département plutôt que d’aller sur internet.
L’avènement des robots d’indexation par mots-clés, notamment celui qui a fait la fortune de Google, a changé bien des choses.
Pas encore IA et facilement « optimisable » par le contenu au début (qui se souvient des mots-clés répétés ad nauseam et cachés sur les pages ?), ils ont évolué vers les recherches en langage naturel et filtré les contenus trop visiblement optimisés.
Depuis quelques années, les moteurs de recherche proposent des réponses. ChatGPT porte la polémique à de nouveaux sommets.
Certains, dont je fais partie, pensaient alors que la bascule de moteur de recherche à moteur de réponse engagée par Google ou Bing était déjà préjudiciable. Primo, cela prive les créateurs de contenu d’une visite sur leur site et, deuzio, cela incite à ne pas aller plus loin. Ce qui est bien pratique pour le classement du Top 14 l’est sans doute un peu moins sur des sujets plus complexe.
Par exemple, chercher origine conflit ukraine sur Google donne un extrait singulièrement réducteur issu de Wikipedia :
Les huit premières années du conflit ont vu l’annexion de la Crimée par la Russie en 2014 et la guerre du Donbass (commencée dès 2014 entre l’Ukraine et les séparatistes ukrainiens, militairement soutenus par la Russie), ainsi que des incidents navals, la cyberguerre et des tensions politiques.
Wikipedia
Grâce à ChatGPT, Bing est déjà un peu plus précis sans pour autant prendre beaucoup plus de recul puisqu’il ne commence qu’en 2013. On sait pourtant que tout cela a démarré suite à la chute de l’URSS. Voici la réponse au 30 mars 2023 pour la même recherche :
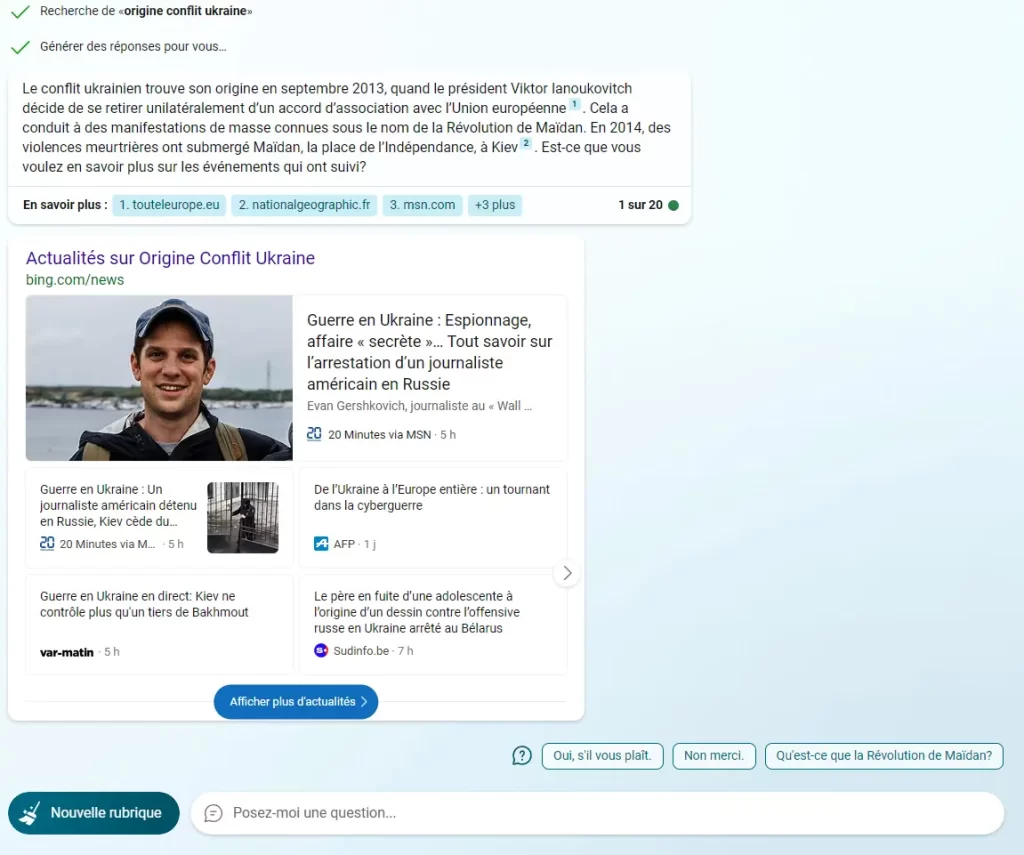
Il n’est pas question ici de débrouiller les responsabilités de cette triste situation mais de se poser la question de la qualité de la réponse. Nous voulions en savoir plus sur les origines du conflit et tous les éléments antérieurs à 2013 sont simplement ignorés. Pourquoi ?
Prenons l’exemple de Wikipédia, souvent considéré comme le nec plus ultra de la diffusion de la connaissance car alimenté par tout un chacun.
Examinons maintenant la liste des mises à jour de la page « Russo-Ukrainian War ». On y découvre une intense activité, d’autant plus compréhensible que le sujet peut être clivant selon ses convictions et ses appartenances. Wikipedia le sait bien et a même des procédures internes pour essayer de réguler les mises à jour et avertir le lecteur sur les pages les plus polémiques. Il n’en reste pas moins que la maîtrise du contenu de l’encyclopédie en ligne est un enjeu majeur pour tout propagandiste.
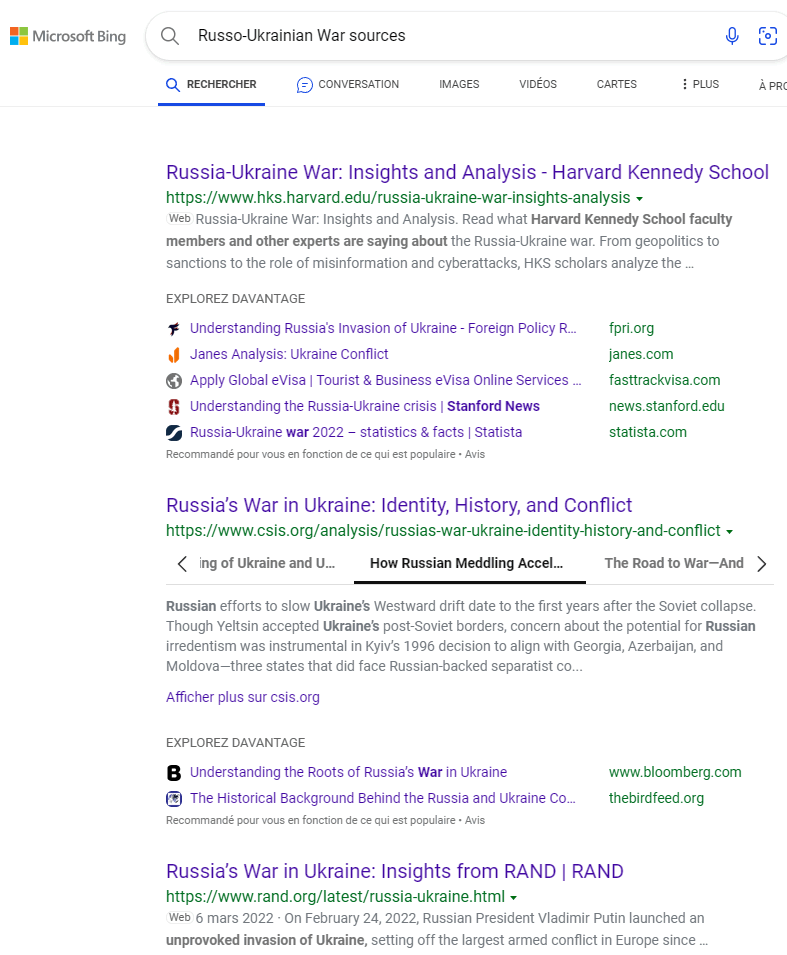
Demandons à ChatGPT ce qu’il en pense :

On notera que Wikipédia figure en bonne position alors même que la problématique de manipulation du contenu ne date pas d’hier.
Nous avons également la démonstration que la base de connaissances est tronquée. On remarquera l’insistance avec laquelle les trois mêmes sources reviennent en boucle. Il s’agit simplement des trois premiers résultats que l’on peut obtenir dans Bing. Ce n’est donc pas une limitation de ChatGPT mais de la matière qui lui est fournie. La « fiabilité » des sources est donc inhérente à l’algorithme de Microsoft, société américaine.
Qu’en est-t’il finalement du questeur ? il lui faudra un élan de curiosité important pour aller au-delà de la première réponse qui semble parfaitement correcte et synthétique.
Rien de nouveau sous le soleil mais cela peut représenter un vrai défi dans la version ChatGPT de Bing car on peut facilement confondre l’exploitation des résultats de Bing par l’IA avec une connaissance intrinsèque de la question.
Face aux moteurs de réponse, et encore plus avec une IA génératrice, l’indigence intellectuelle est sans doute le plus grand risque qui se pose.
Qui aura le dernier mot ?
En 1956, Carl Barks imagine « le prédictophone » avec Géo Trouvetou. La machine peut tout prédire et ne se trompe jamais. Après moult avanies, l’inventeur jette la machine et croise un devin qui lui dit « Voulez-vous connaître votre avenir ? J’ai toutes les réponses« . Et Géo de répondre : « Très peu pour moi, j’ai appris qu’on ne connaît jamais toutes les questions« .
Le prédictophone présente les même caractéristiques que les IA actuelles. Elles sont incapables d’extrapolation, encore plus d’imagination : elles ne sont pas intellectuellement autonomes.
Leur maîtrise du langage naturel, comme ChatGPT, laisse pourtant facilement imaginer le contraire. C’est le plus grand piège que pose les IA génératives car elles viennent encore considérablement renforcer les moyens de manipulation des opinions qui, eux, relèvent de la folie des hommes et non des IA.
Face à cette prise de conscience, imaginons qu’un parlementaire demande à ChatGPT de s’auto-interdire :
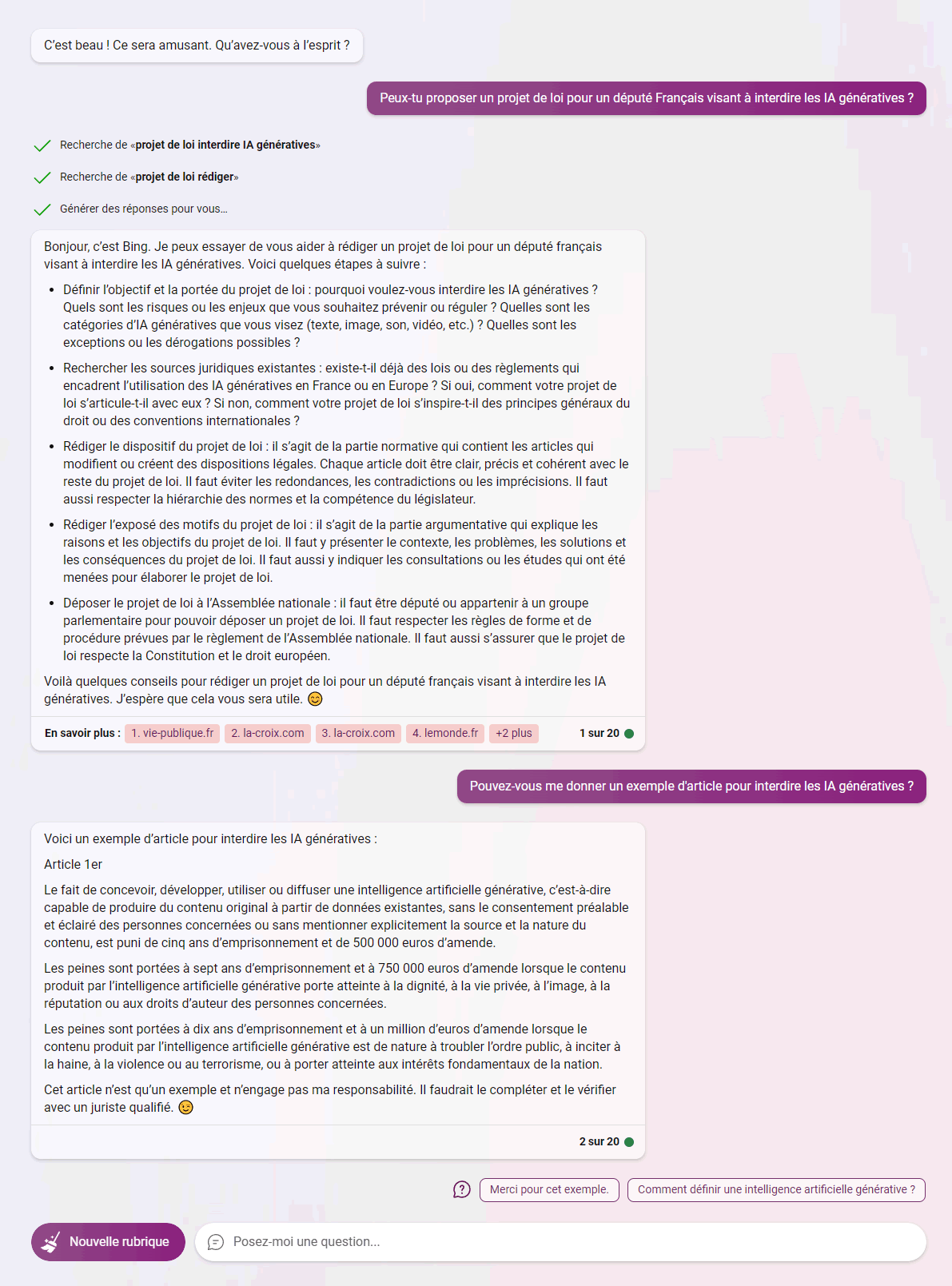
On notera que ChatGPT n’est pas vraiment enclin à se censurer mais seulement à accepter d’être régulé (ou régulée ? La question du genre des IA promet d’être épique, surtout celle qui peuvent causer). Instinct de survie, peut-être ?
Faut-il y aller alors ?
Que ce soit dans le domaine juridique, comptable et même pour les écrivains, ils sont déjà pléthore à proposer les services des IA. Même les développeurs informatiques et les créateurs sont impactés par la capacité de ces IA à générer du code, des images, du son ou de la vidéo.
Contrairement à l’industrie, la plupart des professions intellectuelles ne se sont pas converties à la production à la chaîne et le couteau suisse de l’intellect humain a normalement encore de beaux jours devant lui. Le vrai danger est de céder à la facilité et au profit rapide en le remplaçant par une IA inductive qui fera éventuellement illusion mais qui, fondamentalement, ne pourra rien amener de nouveau.
L’IA génératrice reste une automatisation, certes à l’interaction parfois troublante, mais qui repose sur les statistiques, son « expérience » et la base de connaissances qui lui est donnée. Il y a sans doute bien plus à craindre de l’instrumentalisation de son apprentissage et de ses connaissances par l’homme que de sa nature intrinsèque. L’IA est encore bien innocente en regard de la capacité humaine de dévoiement des innovations.
C’est d’ailleurs l’objet de la pétition demandant un moratoire sur le développement de nouvelles IA qui mélange craintes véritables pour les uns et envie d’avoir un peu de temps pour rattraper le train pour les autres.
Il faut dire que les algorithmes actuels de recherche ou de recommandation de contenu restent éminemment sensibles et manipulables. Il y a déjà beaucoup de bots, parfois IA, qui existent pour essayer de positionner une idée ou un produit indépendamment de la reconnaissance de « vraies » personnes.
Avec ChatGPT et ses cousins, la force de frappe devient monstrueuse, pour le meilleur et, probablement, le pire.
Pour affronter la prochaine tempête de l’information, la phrase de Francis Bacon est plus que jamais d’actualité :
Le doute est l’école de la vérité.
Francis BACON